Large Language Models: Revolutionizing AI and Reshaping Our Digital Future
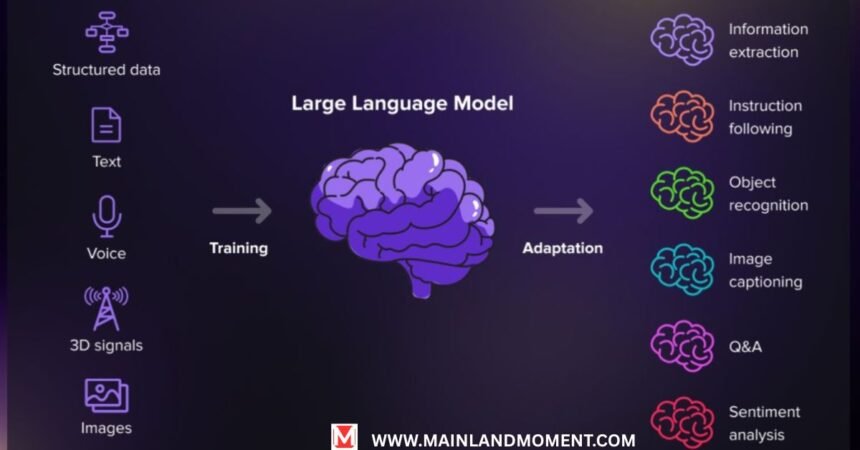
Large language models are revolutionizing the way we interact with technology, reshaping industries, and unlocking new possibilities previously confined to science fiction. These sophisticated neural language models have grown exponentially in capability, enabling machines to understand and generate human language with remarkable fluency.
From writing code to creating content, translating languages to powering customer care systems, large language models have become the backbone of modern generative AI. As these foundation models continue to advance, they’re not just changing how artificial intelligence functions they are fundamentally altering our relationship with technology, raising profound questions about creativity, work, and even what it means to communicate.
This article explores the fascinating world of large language models and their impact on our digital future.
What are LLMs?

Large language models are advanced AI systems trained on massive datasets of text from across the internet and other sources. Unlike earlier, more limited natural language processing tools, modern LLMs can understand context, generate human-like text, translate languages, write code, and even demonstrate creative abilities.
"Large language models represent the convergence of decades of research in artificial intelligence, computational linguistics, and machine learning. They're not just incremental improvements—they're a quantum leap in capability." — Dr. Emily Bender, Computational Linguist
What sets modern large language models apart from their predecessors is their foundation in transformer architecture, which enables them to handle contextual relationships between words and concepts across lengthy passages of text. This advancement marked a pivotal moment in the development of natural language processing.
Evolution of Language Models

The scale of training data has also expanded dramatically. While early models might have trained on books or specific collections of text, today’s large language models consume diverse content equivalent to millions of books, including articles, websites, code repositories, and more. This broad exposure enables them to develop general-purpose capabilities that can be applied across domains.
How Large Language Models Work
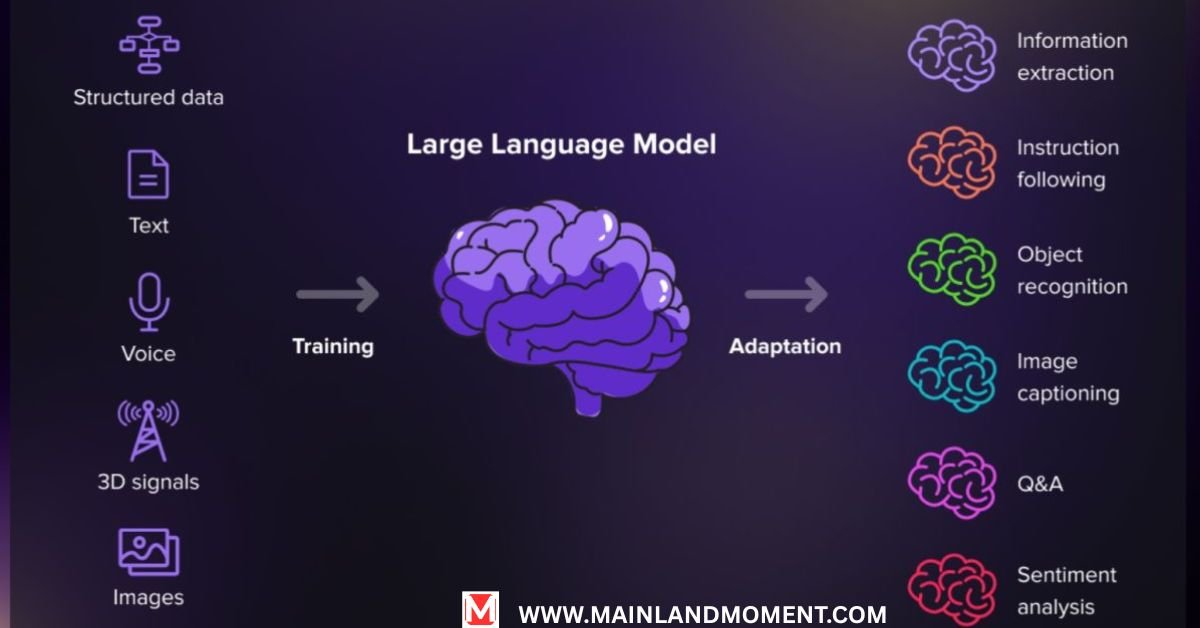
At their core, large language models are built on neural networks—specifically transformer architectures—that process and generate text by predicting the probability of what comes next in a sequence. But understanding how they actually work requires diving a bit deeper.
The Transformer Architecture
The breakthrough behind modern generative AI came in 2017 with the publication of “Attention Is All You Need,” which introduced the transformer architecture. This design replaced previous sequential processing methods with a mechanism called “self-attention,” allowing models to weigh the importance of different words in relation to each other—regardless of their position in a sentence.
For example, in the sentence “The trophy wouldn’t fit in the suitcase because it was too big,” a transformer can determine that “it” refers to “the trophy” rather than “the suitcase” by attending to the semantic relationships between these words.
Key components of transformer-based large language models
- Self-attention mechanisms that capture relationships between words
- Multi-headed attention that allows the model to focus on different aspects of input simultaneously
- Feed-forward neural networks that process the attended information
- Positional encoding that helps the model understand word order
- Layer normalization that stabilizes the learning process
The Training Process
Training large language models involves two main phases:
- Pre-training: The model learns general language patterns by predicting missing words or next words from vast text corpora. This creates what we call foundation models—versatile AI systems that can be adapted to many downstream tasks.
- Fine-tuning: The pre-trained model is further refined on specific datasets, often with human feedback, to improve its capabilities for particular applications or to align it with human values.
This process requires enormous computational resources. Training leading machine learning models like GPT-4 can cost tens of millions of dollars in computing power alone, using specialized hardware like graphics processing units (GPUs) and tensor processing units (TPUs).
Why Foundation Models are a Paradigm Shift for AI
Foundation models represent a fundamental shift in how we approach artificial intelligence development. Instead of building specialized systems for individual tasks, researchers now create versatile base models that can be adapted to countless applications.
Emergent Abilities
Perhaps the most fascinating aspect of large language models is their demonstration of emergent abilities—capabilities that weren’t explicitly programmed but appear once models reach sufficient scale. For instance, early smaller models couldn’t perform basic arithmetic, but larger versions suddenly demonstrated mathematical reasoning abilities.
Other examples of emergent capabilities include:
- Multi-step reasoning
- Zero-shot learning (performing tasks without specific examples)
- Few-shot learning (learning from just a few examples)
- Understanding implicit instructions
- Cross-domain knowledge application
Dr. Percy Liang of Stanford’s Center for Research on Foundation Models notes: “What’s remarkable about these foundation models is that we often don’t know their full capabilities until we probe them in new ways. They continually surprise us with abilities that weren’t explicitly built in.”
Economic and Research Implications
The rise of foundation models is reshaping the AI landscape economically as well. While developing these models requires substantial resources, once built, they can be fine-tuned for specific applications at a fraction of the original cost. This creates both democratizing effects and potential concentration of power.
For researchers, large language models serve as accelerators for discovery across fields. Scientists in domains from biology to climate science are using these tools to generate hypotheses, analyze literature, and speed up experimentation.
LLM Use Cases
The versatility of large language models has led to a wide range of applications across industries. Here’s how these neural language models are transforming various fields:
Content Generation
Content generation represents one of the most visible applications of large language models. These systems can:
- Draft articles, emails, and reports
- Generate creative fiction and poetry
- Create marketing copy and product descriptions
- Summarize long documents
- Adapt content for different audiences and tones
For content creators, generative AI systems are specialists who can provide assistance overcoming writer’s block, offer new phrasing or generate writing tasks for the day.
Code Generation
Large language models have revealed their remarkable talent in code generation and programming assistance. Tools such as GitHub Copilot and Amazon CodeWhisperer have been powered by large language models to do the following:
- Generate functions based on comments or specifications
- Complete partial code
- Suggest bug fixes
- Convert between programming languages
- Explain complex code
Case Study: Productivity Gains at Accenture
When Accenture deployed code generation tools based on large language models to their development teams, they reported:
- 30% reduction in time spent on routine coding tasks
- 25% faster onboarding for new developers
- 40% increase in first-time code quality
Enterprise Applications
In business settings, large language models are transforming operations through:
- Customer care automation that can handle complex inquiries
- Document analysis and contract review
- Meeting summarization and action item extraction
- Knowledge management and internal documentation
- Market research and competitive analysis
Embracing technology would therefore be rather misplaced if one were to defend against the charge of laxity; indeed, the banking sector has been rather prompt in adopting these technologies. JPMorgan Chase has set up a system named IndexGPT allowing employees to use natural language to query a huge firm’s research database rather than searching complex parameters.
Education
In educational contexts, large language models are creating personalized learning experiences through:
- Customized tutoring that adapts to individual learning styles
- Generating practice problems at appropriate difficulty levels
- Providing detailed explanations of complex concepts
- Creating educational materials in multiple languages
- Giving feedback on student writing
Healthcare
The healthcare industry is carefully exploring applications of large language models for:
- Medical literature research and summarization
- Drafting clinical notes and documentation
- Preliminary triage of patient symptoms
- Explaining complex medical concepts to patients
- Analyzing healthcare data for patterns
LLMs and Governance

The discussion of governance, ethics, and regulation is becoming all the more salient in an age where large language models have become increasingly powerful and widespread.
Ethical Considerations
Large language models raise several ethical concerns that require careful consideration:
- Bias: Models can perpetuate or amplify biases present in their training data
- Misinformation: The ability to generate convincing text raises concerns about synthetic content
- Privacy: Training data may contain sensitive personal information
- Attribution: Questions around ownership of AI-generated content
- Access disparities: Unequal access to these powerful tools
Safety Frameworks
Leading AI labs have developed various approaches to making large language models safer:
- Reinforcement Learning from Human Feedback (RLHF) to align models with human values
- Constitutional AI methods that use principles to guide model behavior
- Red-teaming exercises where experts try to make models produce harmful outputs
- Monitoring systems that detect problematic usage patterns
Prompt engineering is an important domain aiming for designing prompts that yield useful, safe, and faithfully correct outputs from substantial language model parameters.
Regulatory Landscape
Governments worldwide are working to develop appropriate regulatory frameworks for artificial intelligence and large language models specifically:
- The EU’s AI Act categorizes applications based on risk levels
- The US has released an AI Bill of Rights as non-binding guidance
- China has implemented regulations on algorithm recommendations and synthetic content
- International organizations are working on global standards
The Road Ahead
The field of large language models continues to evolve rapidly, with several key trends shaping its future:
Technical Frontiers
Researchers are pushing large language models in several exciting directions:
- Multimodal capabilities that combine text with image, audio, and video understanding
- Extended context windows that allow processing of much longer documents
- Improved reasoning abilities through specialized training techniques
- More efficient architectures that reduce computational requirements
- Integration with external tools and databases
Societal Integration
As large language models become more capable, we’ll need to navigate:
- Educational shifts to prepare students for an AI-augmented workforce
- New professional roles centered around human-AI collaboration
- Updated information literacy skills for a world with synthetic content
- Evolving creative practices that incorporate AI assistance
“The most successful organizations won’t be those that simply deploy large language models, but those that reimagine their processes to leverage the unique capabilities these systems offer.” — McKinsey Global Institute
Beyond Language
The principles behind large language models are expanding beyond text to other domains:
- Visual generation models creating images and videos
- Scientific models for protein folding and drug discovery
- Engineering models for materials design and optimization
- Music and audio generation systems
Conclusion
Large language models have emerged as very much the most significant advancement in technology over the past decade. Their reach extends beyond mere technical achievements to some very fundamental questions on the future conduct of humankind as a whole: the ways by which people will work, create, and communicate.
The advancement of these systems also needs to keep the conversation with not just the technical experts but with people from all backgrounds who will be affected by it. If the development of large language models is approached in a reflective sense, it would both allow for and bring to light some very serious concerns. For example, how are we able to mitigate harm by enacting specific regulations and supporting the integration of AI in society to create benefits.





{kind=link}